BeforeUp
Here is an example of an entry from a source (titled Lenje Handbook) that we have acquired:
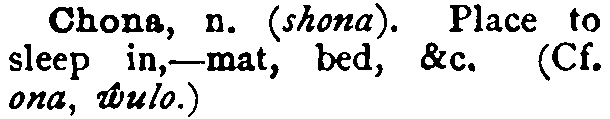
Let’s see what you, as a PanLex developer, might typically do to this entry. (Don’t worry if it’s partly unclear now; explanations are on other pages.)
Step 1
First, you select the PanLex-relevant information, standardize it, and put it into the form of a row in a table (tabularization). Here are some possible ways to do this:
Simple:
chona mat=bed
A little more detailed:
chona n mat=bed
Even more:
chona n mat=bed place to sleep in (mat, bed, etc.)
Really ambitious:
chona n mat=bed art-314:location_of:eng-000:sleep
Super-ambitious: combine the last two above into a row with 5 columns.
Step 2
Second, you convert the table into a sequential format (serialization). If you chose the simple version above, the result looks like this:
mn
dn
leh-000
chona
dn
eng-000
mat
dn
eng-000
bedIf you were really ambitious, the result looks like this instead:
mn
dn
leh-000
chona
dcs2
art-303
PartOfSpeechProperty
art-303
CommonNoun
dn
eng-000
mat
dn
eng-000
bed
mcs2
art-314
location_of
eng-000
sleepStep 3
Third, you submit your serial file for importation into the PanLex database.
After
After you have performed steps 1, 2, and 3, there are new records in several tables of the database. If you chose the super-ambitious version, here is what you have added from this entry:
- If “chona” in language variety
leh-000(Lenje) isn’t already an expression in the database, a new record for that expression in tableex. - A record for the new meaning of source
leh-eng:Madanin tablemn. - 3 new records for denotations of that meaning, assigning it to each of the 3 expressions (“chona”, “mat”, and “bed”) in table
dn. - A record for a definition of that meaning in language variety
eng-000(English) in tabledf. - For the “chona” denotation, a record in table
dcsclassifying the denotation as belonging to class “CommonNoun” in superclass “PartOfSpeechProperty”. - A record in table
mcsclassifying the new meaning as belonging to class “sleep” in superclass “location_of”.
As a result, users of PanLex can find new information. For example, a user wanting to translate “အိပ်ရာ” from Burmese into Lenje can get “chona” as a distance-2 translation.
What did you do?
To understand fully the example above, you need to study the documentation in this assimilation section. But here are a few points:
- You decapitalized “Chona”, because capitalizing the Lenje expressions is part of this source’s style, not part of any Lenje orthographic standard.
- The form “shona”, the source says in its introduction, is a plural form, so you omitted it, knowing that PanLex is a database of lemmatic translations.
- You also omitted the words introduced by “Cf.”, as being of little value to PanLex.
- You chose whether to omit “a place to sleep in”, treat it as a definition, treat it as a meaning classification (“really ambitious”), or both (“super-ambitious”). The meaning classification takes more time to create than the definition, but also has more potential value.
- Are “bed” and “mat” good translations of “chona”, or only examples? You could have refused to make denotations from them, but this could in practice prevent users from finding a Lenje translation of “bed”. By not demanding “perfection”, you brought the world one step closer to being able to express any concept usefully in any language.