IntroductionUp
Normalization is the process of checking expressions before they are entered into PanLex in order to promote orthographic consistency and screen out bogus expressions. For instance, in different sources the same expression might be written with whitespace characters (e.g. “chicken pox”), with a hyphen (“chicken-pox”), or as a single word (“chickenpox”). If you normalize such expressions, you create more connections in the database, facilitating translation inference. Alternatively, a source might contain strings such as “red dwarf”, “red ink”, and “red lipstick”. The first two are genuine lemmas (at least with certain senses), but the third isn’t. If you accept the former but revise the latter to “lipstick” with “(red) lipstick” added as a definition, you again enhance the ability of PanLex to support translation inference.
Script
The normalize serialization script interrogates the database to perform some of this normalization. For example, it can determine that “chickenpox” is the consensus form and that only one PanLex source attests “red lipstick” as an expression but many sources attest “red dwarf” and “red ink”. The script can convert deviant forms to preferred forms and can convert fatally deviant expressions to definitions.
Normalizable properties
Not all properties of expression texts are handled by normalize. At present it doesn’t have access to language-specific data on lexical alternates. Instead, it relies on the PanLex degradation algorithm to identify similar forms.
Normalization is appropriate mainly for language varieties with many expressions already in the PanLex database. Typically, these are major world languages (English, French, Spanish, Chinese, etc.). The normalize script within the serialize.pl script permits a few parameters to be set by the editor (see below).The richer the data for a language variety are, the higher you can set the minimum-score parameters and get plausible results. The normalize script can run on only one column at a time. If you want to perform normalization on more than one column, you can duplicate the line that calls normalize in serialize.pl so it will be invoked multiple times, referring to a different column, and possibly with different parameters, each time.
To normalize or not?
You shouldn’t always use normalization, even on richly documented language varieties. If you are analyzing a trusted source, it may be better to skip normalization, so that the source is permitted to add new expressions to the database and dictate the forms of expressions.
Parameters
Other than the column of the tabularization file to apply normalization to, and the language variety of the expressions contained within that column, the main input parameters for the normalize script are as follows:
min
This is the minimum score (essentially, a number representing the frequency of the expression already in PanLex) that a proposed expression must have in order to be accepted outright as an expression. A proposed expression with a lower score than min will be replaced by its highest-scoring degraded form (provided that this degraded form itself has a score exceeding a minimum value set by the parameter mindeg).
mindeg
This is the minimum score that the degraded form of a proposed expression must have in order to be accepted as an expression.
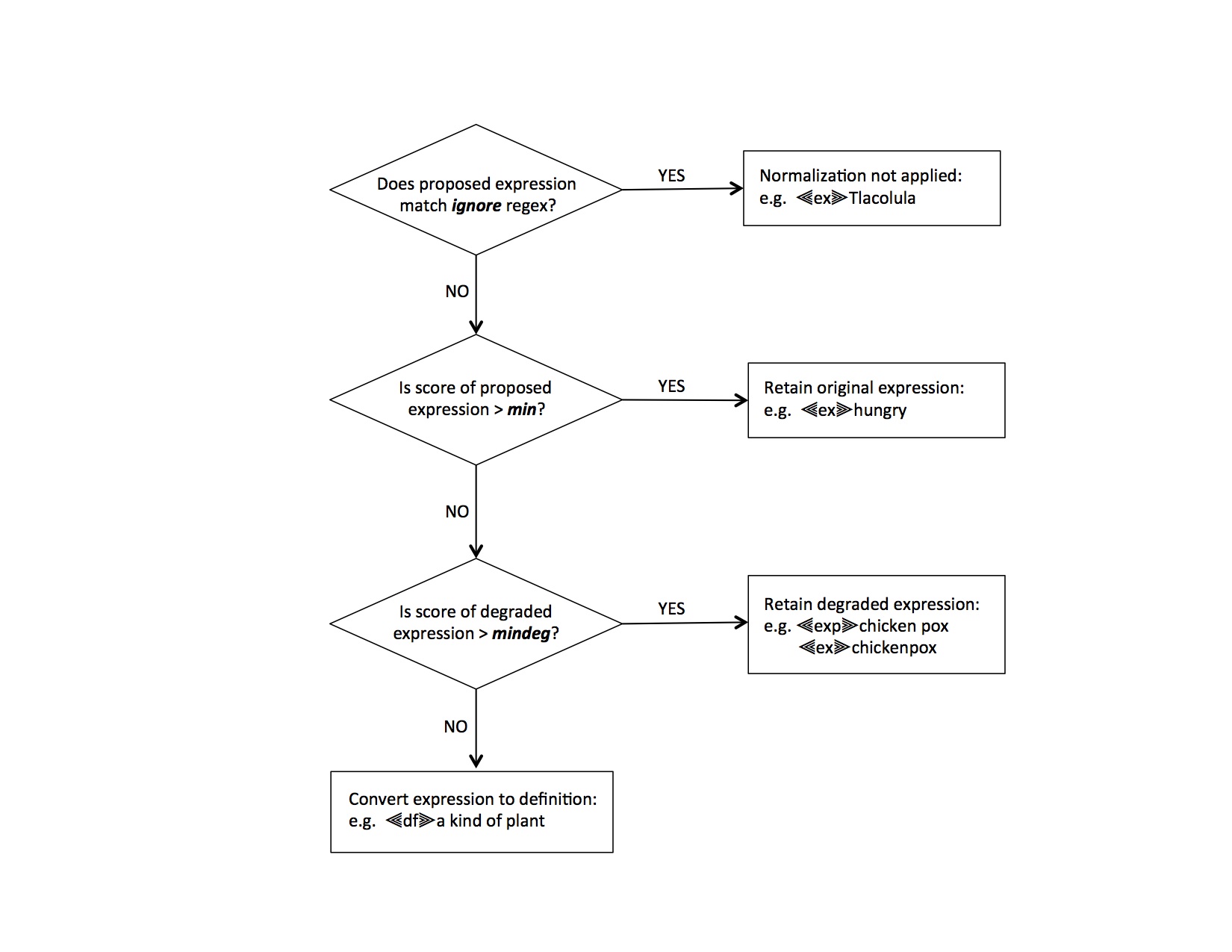
If a proposed expression does not have a score greater than min, but has a degraded form with a score higher than mindeg, the original expression will be retagged with the pre-normalized expression tag ‘⫷exp⫸’, and the highest-scoring degraded form will be tagged as an expression. For example:
⫷ex⫸chicken-pox => ⫷exp⫸chicken-pox⫷ex⫸chickenpox
The values of the min and mindeg parameters will vary with the language variety. For English expressions – the most attested language for expressions in PanLex – reasonable values for min and mindeg are 50 and 10, respectively, whereas for Spanish, values of 30 and 7 are more appropriate. However, these are not hard-and-fast parameter values, and the editor can experiment with min and mindeg in order to get the best results.
log
This optional parameter is useful for determining the optimal values of min and mindeg for a particular source. If set to 1, a log file in JSON format called normalizeX.json (where X is the column index) will be produced containing the normalization scores returned from the PanLex API (see here for a description of the format). Exact scores are shown under stage1, degraded scores under stage2.
failtag
Proposed expressions that fail to meet the minimum requirements of both min and mindeg will not be accepted as expressions in PanLex. By default, these expressions will be converted to definitions and tagged with the ‘⫷df⫸’ tag. However, the editor is able to set the failtag parameter to some other tag, if desired. For instance, if the editor is sure that the source is highly reliable and does not want to reject any low frequency vocabulary in the source that is not already attested in PanLex, she might set the parameter failtag to ‘⫷ex⫸’. By doing this, the editor is trusting every expression in this language variety in the source to be an expression, but is allowing PanLex to substitute an alternative form (differing in letter case, spacing, diacritical marks, and/or punctuation) that is better-attested.
propcols
This optional parameter is a list of columns to which the change to failtag should be propagated. It is useful if you expect that invalid expressions in one column will typically be invalid expressions in another column. For example, suppose that the English column sometimes translates a less common language variety’s expression with full sentences such as ‘the apple ripened’, ‘the bell jingled’, ‘the dog barked’, and so on. These are likely to be non-lemmatic in the less common variety as well. You can use use normalize to detect non-lemmatic English expressions and propagate the change of ‘⫷ex⫸’ to ‘⫷df⫸’ to the other column.
Propagation requires that all the expressions fail normalization. If the column contains multiple expressions and at least one of them survives, propcols doesn’t propagate.
ignore
This optional parameter is a regular expression matching any expression that should be ignored by the normalization process. For example, if a source contains capitalized expressions that are the proper names of local villages, gods, holidays, etc., it may be appropriate for these to be ignored by the normalization process and thereby accepted as expressions by PanLex even if these are not already attested in PanLex. In this particular case, the ignore parameter would be set to ‘^[A-Z]’.
You can use the ignore parameter to exempt particular expressions from normalization. Choose any mark that isn’t already in the source file, attach it to the expressions that you wish to exempt, and give the ignore parameter a value that will match it. For example, prefix the expressions with ‘ok:’ and set the value of ignore to ‘^ok:’. This leaves the marked expressions as-is, marks and all. To remove the marks, use the replace script, changing ‘\bok:’ to the empty string. (Using ‘^ok:’ would not work, since replace replaces over the whole column, and the column begins with an expression tag.)
ui
This optional parameter is a list of the IDs of one or more source groups that should be ignored by the normalization process. Typically, you should use this parameter if you are re-analyzing an already imported source. By specifying that source’s group ID, you can ensure that the scores assigned to its expressions are not inflated by the fact that the source is already in PanLex.
Classification normalization
It is possible to run normalize on the class expression of a meaning or denotation classification. To do so, you should set the extag parameter (normally ‘⫷ex⫸’) to ‘⫷mcs⫸’ or ‘⫷dcs⫸’. If the class expression’s UID is already tagged you will have to specify it as well, for example ‘⫷mcs:eng-000⫸’.
You should also set the failtag parameter. If you set failtag to ‘⫷mpp⫸’ or ‘⫷dpp⫸’, class expressions that fail normalization will have their class expression converted to a property text and their superclass expression converted to an attribute expression. For example, ‘⫷mcs2:art-300⫸IsA⫷mcs⫸large spider’ would become ‘⫷mpp:art-300⫸IsA⫷mpp⫸large spider’. If you set failtag to ‘⫷mcs⫸’ or ‘⫷dcs⫸’, only the class expression’s tag (including any language variety specified in failtag) will be affected. If you set failtag to any other tag, it will replace the class expression tag, while the superclass expression will be removed. For example, with failtag set to ‘⫷rm⫸’, ‘⫷mcs2:art-300⫸IsA⫷mcs⫸large spider’ would become ‘⫷rm⫸large spider’. (The special tag ‘⫷rm⫸’ indicates that the tag and its contents should be removed in the final source file.)
The flow of normalization
In summary, the logic of the normalize script is shown in this diagram (assuming the default option for failtag):